
Evitar que los grandes modelos degeneren
Con el éxito de modelos de IA generativa como ChatGPT para texto o StableDiffusion para imágenes, hay muchos contenidos que se crean sintéticamente y se publican en Internet.
Para entrenar y afinar esos modelos, la mayoría de los datos se recogen de Internet.
¿Qué ocurre cuando la nueva generación de modelos se entrena con datos sintéticos?
El problema de la locura
MAD es el acrónimo de Model Autophagy Disorder y en inglés funciona muy bien para describir el problema.
Un estudio reciente, Self-Consuming Generative Models Go MAD, puso a prueba esta cuestión antes mencionada. Definió que los modelos que se entrenan recursivamente sobre datos sintéticos se vuelven “locos” (MAD). El resultado de esos modelos es, en general, una menor variedad de generación de contenidos o/y una menor calidad de los mismos. Pero la comprensión de las ramificaciones causadas por ese tipo de modelos sigue siendo escasa.
Hay tres formas posibles de entrenar modelos con datos sintéticos:
- Entrenamiento solo con datos sintéticos
- Entrenamiento con una cantidad fija de datos reales y sintéticos.
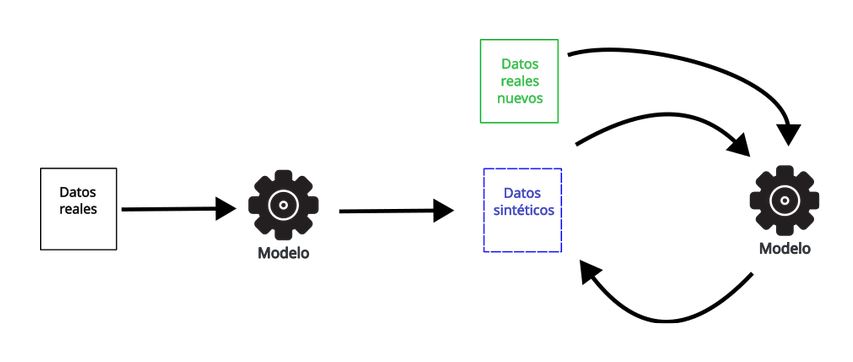
- Entrenar con datos sintéticos y una cierta cantidad de datos reales nuevos..
En el primer caso, en el que un modelo se entrena sólo con datos sintéticos y utiliza cada vez su propio contenido para entrenar la siguiente iteración del modelo generativo, se produce rápidamente una degradación de la calidad y la diversidad del contenido producido.
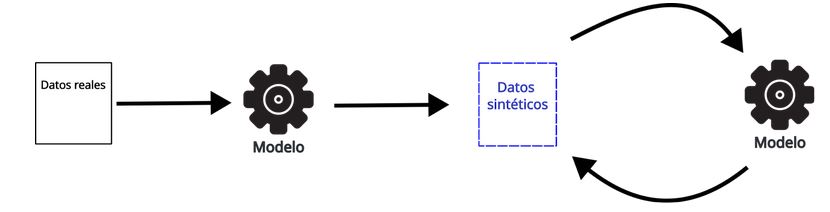
Cuando el modelo se entrena en cada iteración con una cantidad fija de datos reales, la degradación de los modelos sigue siendo inevitable, pero se retrasa.
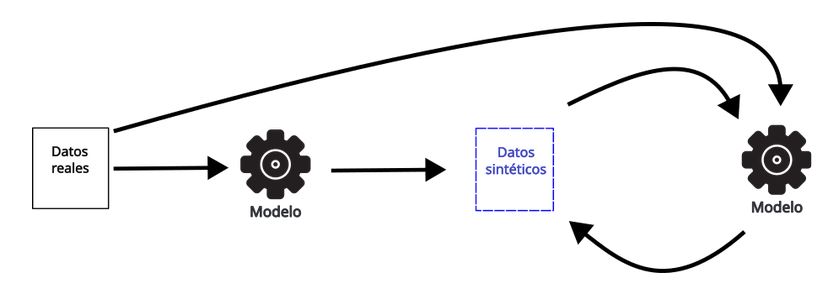
Y, por último, cuando los modelos se entrenan siempre con una cantidad mixta de datos reales frescos, parece que la calidad y la diversidad de los modelos se mantienen en cada iteración.
¿Por qué ocurre esto?
Los modelos intentan aprender de los datos que ingieren y luego intentamos que generen lo que generarían los humanos. La intención es que los modelos aprendan de los humanos. Pero una vez que los datos que consumen proceden de otros modelos, ya no aprenden de los humanos, sino de sí mismos. Esto provoca un efecto parecido a una cámara de eco. La nueva generación de modelos empieza a malinterpretar lo que cree real reforzando lo que ya ha aprendido.
El estudio de Shumailov et al. menciona dos razones:
- Error de aproximación estadística: Donde el número de datos reales empieza a desaparecer a medida que el número de datos sintéticos tiende al infinito. Y la aproximación tiende a ser un error debido al remuestreo de los datos.
- Error de aproximación funcional: Cuando el error proviene de intentar ajustar al problema un modelo excesivamente simple o complejo.
Imagina que quieres hacer galletas pero no tienes suficiente harina, así que utilizas una harina sintética que no es tóxica y funciona igual que la harina, pero no sabe a harina. Cuanta más harina sintética sustituya a la real, menos se parecerán las galletas a las de verdad. Este es el error de aproximación estadística: cuantos más datos sintéticos utilices, más lejos estarás de la realidad.
El error de aproximación funcional sería como utilizar una máquina para cortar madera con formas, de dos tipos, o tan simple que sólo corta madera en forma de cubos (y no es lo que queremos), o tan compleja y versátil que resulta imposible de utilizar.
Una combinación de esos dos errores, en particular el error de aproximación estadística, son las que causan este tipo de problemas.
Conclusiones
Con la inevitable difusión del uso de modelos generativos y la distribución de su contenido en línea, es inevitable que las futuras generaciones de modelos de IA se entrenen con datos sintéticos.
Aunque no es imposible entrenar un buen modelo con datos sintéticos, siempre es una buena idea incluir en la mezcla datos producidos por humanos.
En LHF Labs somos expertos en extraer y conservar datos. Uno de los ejemplos es el conjunto de datos esCorpius.





